안녕하세요
오랜만에 인사드립니다.
최근에 회사 일이 너무 바쁜 나머지.. 제가 한 일들을 잘 기록해내지 못했네요.
제목에서 알 수 있듯이, 이번에는 ceph를 구성해봤습니다
이 전에는 gluster를 사용했었는데, 왜 ceph로 바꿨는지 장단점을 비교해보고
ceph 구성 과정을 적어보려고 합니다.
이유는 안보시고 바로 구성 방법으로 가셔도 좋아요.
Ceph로 변경한 이유
변경한 이유를 알아보기 전에 이전에는 glusterFS를 사용한 이유를 알려드릴께요
glusterFS를 사용한 이유: 낮은 컴퓨팅 요구사항
OCI의 무료 한계 + glusterFS가 동기화가 중단되는 문제가 있었습니다.
조금 더 자세히 설명하면, OCI 무료 범위 안에서서비스의 성능을 최대화 하기 위하여Distributed File System의 성능을 약간 희생한 것이죠.
OCI에는 스토리지 용량 한계로 최대 4대 운영이 가능합니다.
OCI에서는 최대 6코어, 램 26GB까지 가능합니다.
이 때 A1 인스턴스는 계정 내에서 최대 4C 24G까지,(4C 24G 한대 또는 1C 6G 4대 가능)
E2는 1C 1G로 두대까지 가능합니다.
OCI에서 가능한한 최대한 많은 리소스를 긁어모으려고 하면
어쩔수 없이 E2 두대와 A1 한대, 또는 E2 두대와 A1 두대를 써야 하죠.
E2의 최단점은 램이 1G까지인데, ceph는 메모리 요구량이 높습니다.
그래서 glusterFS를 사용했습니다.
glusterFS를 이용하면 서비스가 실행되는 머신은 4코어 24G를 할당해줄수가 있기 때문이죠.
ceph로 변경한 이유: glusterFS가 부서짐.
말 그대로.. 부서져서 그렇습니다.
GlusterFS는 ceph보다 요구 사양도 낮지만, 성능도 엄청 낮습니다.
GlusterFS가 구성된 디렉토리에서 nginx docker 컨테이너를 구동하면 4~10분 정도 걸려요.제가
그래서 nginx container를 replicas를 넣었었죠.
그러던 어느날.. 순식간에 구동이 되는겁니다.
glusterFS가 첫 동기화(?) 작업 때문에 오래걸리고,
이제는 정상화 되었나보다! 라고 생각했었지만, 그냥 gluster가 쪼개진것이더라구요.
sudo gluster peer status를 입력하면 몇몇 노드에 gluster state peer rejected (connected)라는 에러가 표시되더군요.
구글링을 해서 해결을 보아도, 며칠 이내로 다시 같은 에러가 발생헀습니다.
물론 저 에러가 나타나도 동기화는 문제가 확인 되지 않았습니다.
하지만 파일과 데이터는 중요하고,
제가 못찾았다고, 무결성이 검증된다는 보장이 되는것도 아니죠.
또.. glusterFS를 구성하기 전부터 gluster를 사용하다가 데이터가 파괴(?)되었다는 글을 많이 보았습니다.
그저 나만 아니면 된다는 생각으로 구성했었을 뿐이죠.
그래서 결국 포기하고 docker swarm도 단일 노드로 변경해서 사용했습니다.
그러다가 High Availability가 필요해짐에 따라 ceph를 알아보게 되었습니다.
E2 머신은 다 지워버리고, A1 1C 5G 두대와 A1 2C 14G 한대로 독커 클러스터와 ceph 클러스터를 구현했습니다.
Ceph 구성방법
구성 환경
시작하기 전에 환경을 말씀드리겠습니다.
클러스터 공통 사양
Oracle Cloud Infrastructure A1 인스턴스
OS: Fedora 38
SSH는 22번 포트로 접근 가능해야 합니다. 전 여태 포트 바꿔서 썼는데, 바꾸면 안되더군요..ㅠceph로 사용할 수 있는 별도 파티션 필요.
btrfs는 / 볼륨의 shirink를 지원합니다.
다른 OS는 어떻게 해야할지 모르겠네요.ㅠ
머신1 & 머신 2
A1 인스턴스 1C 5G
hostname: se4 / se5
머신 3
A1 인스턴스 1C 14G
hostname se3
패키지 설치
cephadm 패키지 설치
Ceph 프로세스들은 OS에 종속되지 않기 위하여 podman으로 작동합니다.
그래서 저는 웹 콘솔에서 보기 위해, 웹 콘솔 플러그인인 cockpit-podman도 설치 했습니다.
sudo dnf install ceph cephadm cockpit-podmanceph repo 설정
이 부분이 좀 어렵습니다.
원래는 cephadm에서 repo도 설정을 해주는데,
여기서 설정해주는 repository를 따라가면 설치가 안됩니다.
왜냐하면 A1 인스턴스는 ARM64(aarch64)이기 때문이예요.
이글 작성 기준으로는 ceph 최신 버전의 이름이 quincy입니다.
이 링크는 cephadm에서 설치해주는 repo의 baseurl 경로입니다.
https://download.ceph.com/rpm-quincy/el9/
이 글 작성일 기준으로, 이 경로의 aarch64에는 패키지가 없습니다.
그래서 설치가 안되요.
aarch64는 el8에서 찾을 수 있습니다.
저는 el8을 repository로 잡았습니다.
sudo tee /etc/yum.repos.d/ceph.repo << 'EOF'
[ceph]
name=Ceph packages for $basearch
baseurl=https://download.ceph.com/rpm-quincy/el8/$basearch
enabled=1
priority=2
gpgcheck=1
gpgkey=https://download.ceph.com/keys/release.asc
[ceph-noarch]
name=Ceph noarch packages
baseurl=https://download.ceph.com/rpm-quincy/el8/noarch
enabled=1
priority=2
gpgcheck=1
gpgkey=https://download.ceph.com/keys/release.asc
[ceph-source]
name=Ceph source packages
baseurl=https://download.ceph.com/rpm-quincy/el8/SRPMS
enabled=0
priority=2
gpgcheck=1
gpgkey=https://download.ceph.com/keys/release.asc
EOFceph 클러스터 구성
cephadm bootstrap
cephadm 명령으로 bootstrap을 시작합니다.sudo cephadm bootstrap --mon-ip 192.168.150.200
-> sudo cephadm bootstrap --mon-ip 192.168.150.200
Waiting for mgr epoch 8...
mgr epoch 8 is available
Generating a dashboard self-signed certificate...
Creating initial admin user...
Fetching dashboard port number...
Ceph Dashboard is now available at:
URL: https://m1:8443/
User: admin
Password: k2que7rser
Enabling client.admin keyring and conf on hosts with "admin" label
Saving cluster configuration to /var/lib/ceph/d6aff22a-193f-11ee-9056-00505690195e/config directory
Enabling autotune for osd_memory_target
You can access the Ceph CLI as following in case of multi-cluster or non-default config:
sudo /usr/sbin/cephadm shell --fsid d6aff22a-193f-11ee-9056-00505690195e -c /etc/ceph/ceph.conf -k /etc/ceph/ceph.client.admin.keyring
Or, if you are only running a single cluster on this host:
sudo /usr/sbin/cephadm shell
Please consider enabling telemetry to help improve Ceph:
ceph telemetry on
For more information see:
https://docs.ceph.com/docs/master/mgr/telemetry/
Bootstrap complete.
ssh public key 복사
bootstrap 과정에서 생성된 ssh public key를 다른 머신에도 복사해줍니다.
ssh-copy-id -f -i /etc/ceph/ceph.pub root@se4
ssh-copy-id -f -i /etc/ceph/ceph.pub root@se5ceph 클러스터에 host(node) 추가
sudo ceph orch host add se5 10.123.23.5 _admin
sudo ceph orch host add se4 10.123.23.4 _adminse3에서 bootstrap을 구동하였으므로 se4와 se5를 추가합니다.
se4와 se5에 _admin 레이블을 할당합니다.
ceph 볼륨 생성
ceph는 파티션이 아닌 블럭 디바이스를 필요로 합니다.
따라서 lvm을 통해 가상의 블럭 디바이스를 행성해줘야 합니다.
제 생각엔 zfs도 블럭 볼륨을 제공하므로, 가능할 것 같네요.
LVM 볼륨을 생성합니다.
모든 머신에서 실행해줘야 합니다.
sudo pvcreate /dev/sda7; sudo pvdisplay
sudo vgcreate cephvg /dev/sda7; sudo vgdisplay
sudo lvcreate --name cephlv --extents 100%FREE cephvgOSD를 생성해줍니다.
sudo ceph orch daemon add osd se4:/dev/cephvg/cephlv
sudo ceph orch daemon add osd se5:/dev/cephvg/cephlv
sudo ceph orch daemon add osd se3:/dev/cephvg/cephlvceph Filesystem을 생성합니다.
ceph는 object storage, file storage, block device를 모두 제공해줍니다.
저는 filesystem으로 마운트 할 예정이므로,
pool을 생성하고, fs를 생성하겠습니다.
저는 zstd를 사랑하기 때문에 zstd로 설정해줍니다.
for i in {osdpool_userdata_meta,osdpool_userdata_data}; do
sudo ceph osd pool create $i
sudo ceph osd pool set $i compression_algorithm zstd
sudo ceph osd pool set $i compression_mode aggressive
done
sudo ceph fs new userdatafs osdpool_userdata_meta osdpool_userdata_datalog rotate 대상의 이름을 바꿔줍니다.
하나의 로그 파일이 커지는 것을 방지하기 위해 log에는 log rotate라는 프로그램이 있습니다.
일정 주기마다 log의 이름을 바꾸고, 새 로그 파일에 로그를 남기게 도와줍니다.
보통은 매일 자정에 실행되며, log 에 날짜를 포함한 이름으로 이름을 바꿉니다.
예를 들어, ceph.log를 ceph-2023-0721.log로 변경하게 되고,
새로 추가되는 log는 ceph.log에 저장되겠죠.
안타깝게도 두개의 log rotate 설정 파일이 하나의 log 파일을 변경하게 설정 되어있습니다.
그래서 logrotate 서비스가 에러가 발생하면서 작동을 안하게 되요.
즉, ceph만의 문제가 아니라 모든 log에 문제를 발생시키는 것이죠.
따라서 logrotate 설정을 변경해줘야 합니다.
sudo sed -i 's|/var/log/ceph/\*.log|/var/log/ceph/ceph.log|g' /etc/logrotate.d/ceph
sudo systemctl restart logrotateceph mgr 설정
ceph dashboard 접속을 위한 설정입니다.
저는 3대의 머신으로 구성했습니다.
각 머신의 hostname은 se3, se4, se5입니다.
이 중 매니저는 설령 3머신에서 구동되더라도
하나의 서버로만 접속이 가능합니다.
예를 들어 se3에서 manager가 작동 중이면,https://se3:8443으로 접속하게 됩니다.https://se4:8443으로 접속을 시도하면 se3로 proxy되는것이 아니라 redirection이 되버립니다.
문제는 모든 기기에게 /etc/hosts를 변경해줘야 한다는 것입니다.
그래서 ceph 앞에 loadbalancer를 두고, 3개의 ceph manager에 대해 health check하게 하였습니다.
그러나.. traefik이나 oracle cloud infrastructure의 loadbalancer는
http 응답코드가 300이어도 정상으로 판단해줍니다.
다행히 se4나 se5의 매니저로 접속하면 se3로 redirection해주는 대신
에러코드를 반환하도록 설정할 수 있었습니다.
먼저 대시보드에 접속한 후에 Cluster - Manager Modules Dashboard - edit 메뉴로 진입합니다.
설정 항목 중 하단에 standby behaviour가 있습니다.
이 항목을 error로 바꿔주시면 됩니다.
ceph mount
ceph manager가 아닌 머신에서 mount
먼저 key들을 복사해와야 합니다.
manager 머신에서 sudo ceph auth get-or-create client.admin를 실행,
이 결과를 sudo nano /etc/ceph/ceph.keyring에 추가해줍니다.
한번 더, manager 머신에서 sudo cat /etc/ceph/ceph.conf를 실행하고,
이 결과를 sudo nano /etc/ceph/ceph.conf하여 추가해줍니다.
이후는 manager 머신에서 mount하는 것과 같이 하면 됩니다.
ceph manager 머신에서 mount
manager에는 이미 키가 설정되어있어서 쉽습니다.
sudo mount -t ceph :/ /mnt/ceph -o name=admin
# fstab은 다음과 같은 형식으로 추가합니다.
10.123.23.3:6789,10.123.23.4:6789,10.123.23.5:6789:/ /mnt/ceph ceph name=admin,noatime,_netdev 0 0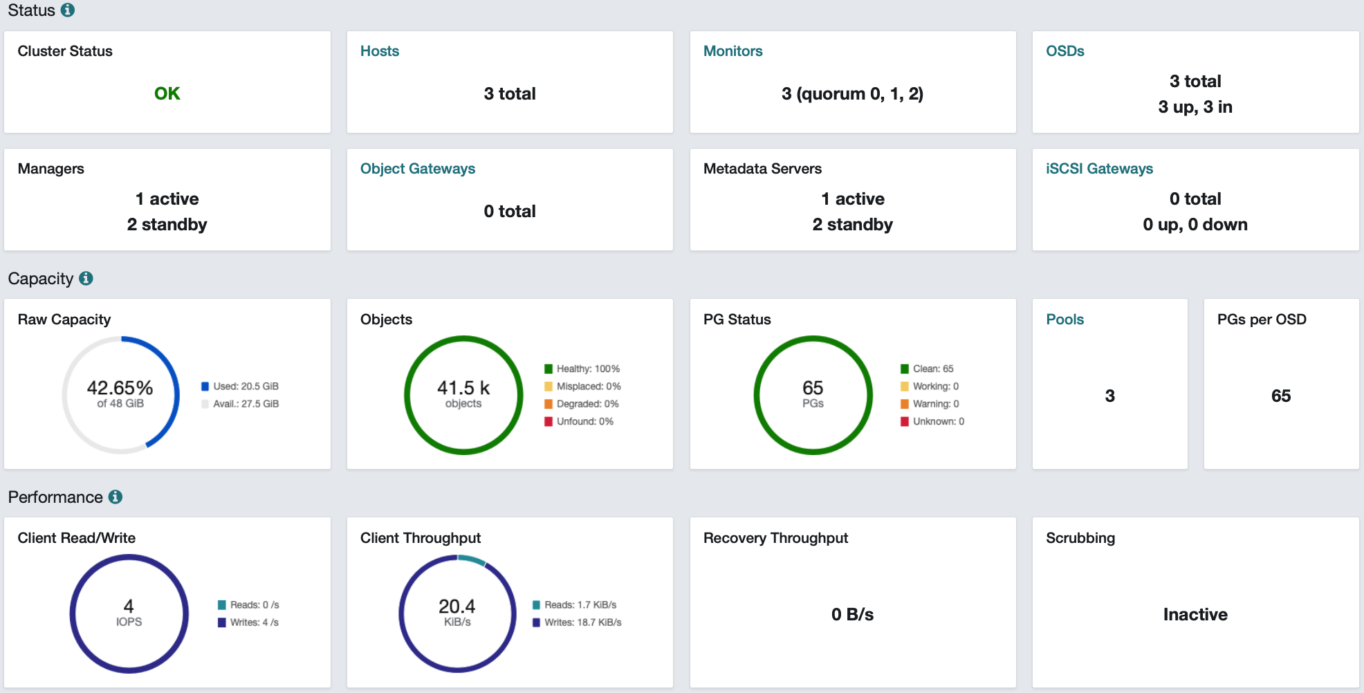

답글 남기기